
Implementierung einer Datenstrategie
Wir sind nun in Phase 2 der Pilotierung des NuDaQ- Vorgehensmodells zur strategischen Implementierung einer Datenstrategie angekommen. Das Modell soll Organisationen (z.B. Krankenhäusern) bei der systematischen Herangehensweise helfen, die vorhandenen Routinedaten für pflegerische Fragestellungen zu nutzen.
NUDAQ Vorgehensmodell – Rückblick Phase 1
Das Modell besteht aus vier Phasen (siehe Abbildung 1) und wird derzeit mit dem Krankenhaus der Barmherzigen Brüdern Salzburg pilotiert und auf Anwendbarkeit evaluiert.
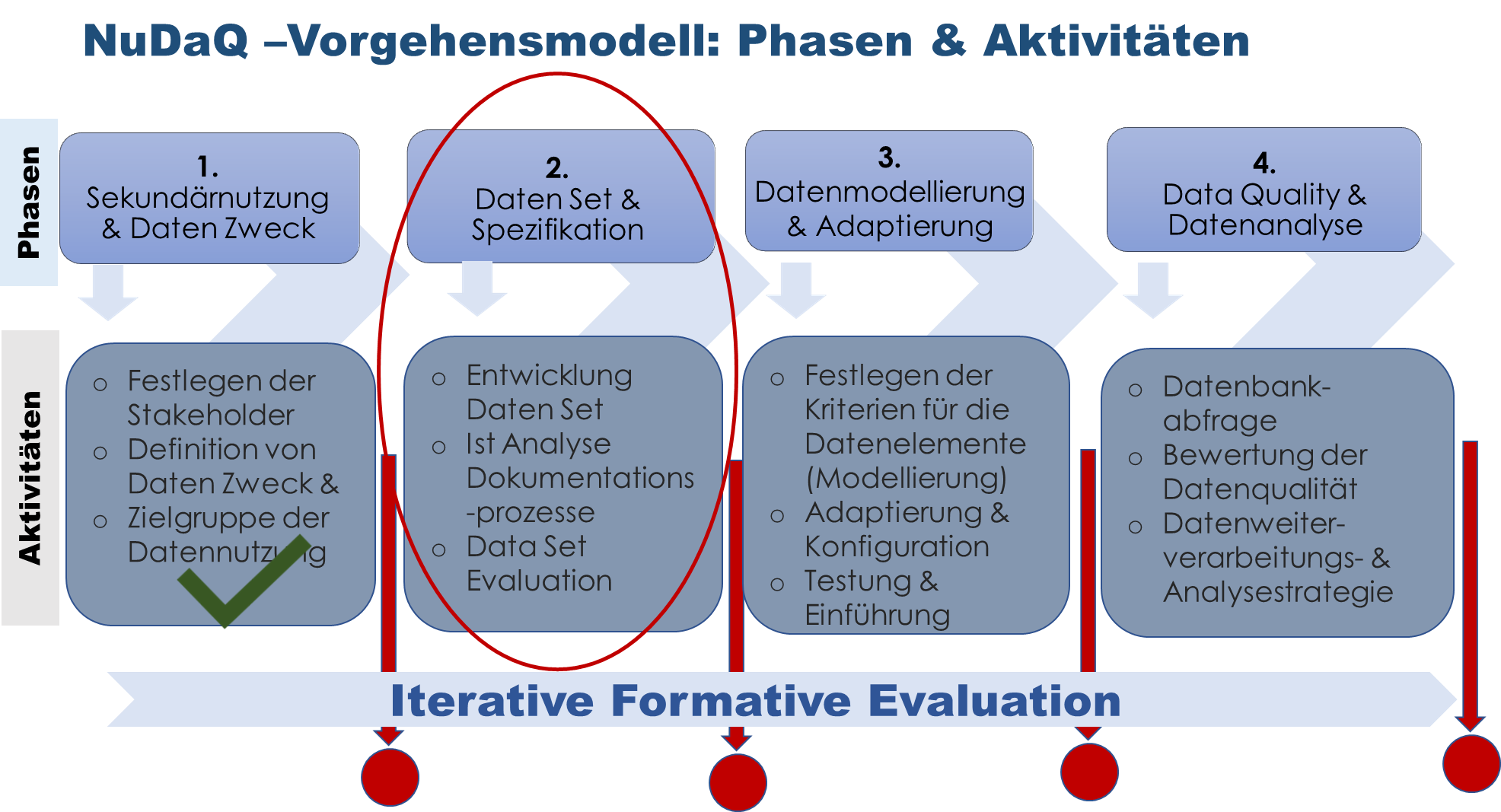
NuDaQ – Vorgehensmodell (aktuelle Version_ 02_2024)
Ziel von Phase 1 war, den Zweck der Sekundärnutzung zu bestimmen. Hier gilt es gemeinsam zu bearbeiten, wer einen Nutzen von den Daten haben soll und welches Themengebiet von Interesse ist. Das Ergebnis aus den Fokusgruppen mit den Stakeholdern hat ergeben, dass sich die Nutzung der Daten auf den Bereich des Schmerzmanagements richten soll. Aus den Analysen der Fokusgruppe ließen sich einige Fragestellungen ableiten. Hier ein paar Beispiele daraus:
- Kann eine adäquate präoperative Aufklärung (PatientInnenedukation), das postoperative Schmerzmanagement der PatientInnen verbessern?
- Welchen Einfluss haben die Schmerzevaluierungsintervalle auf das Schmerzgeschehen?
- Welche Maßnahmen im Rahmen des Schmerzmanagements nehmen am meisten Einfluss auf einen positiven Schmerzverlauf?
- Nach welcher OP ist ein erhöhtes Schmerzgeschehen zu erwarten?
- Welchen Einfluss nehmen gezielte nicht medikamentöse pflegerische Maßnahmen (z.B. Wärme- und Kälteanwendungen) auf das Schmerzgeschehen?
- Ist bei PatientInnen, die bei der Aufnahme bereits schmerztherapeutisch aufgrund eines allgemeinen Schmerzgeschehens behandelt werden, ein verändertes Schmerzgeschehen zu erwarten?
Auf die Frage, wer soll von den Analysen profitieren und wofür könnten die Ergebnisse nützlich sein, konnten folgende Aussagen zusammengefasst werden:
- Alle PatientInnen in Form einer adäquaten Schmerzbehandlung nach operativen Eingriffen.
- Alle Pflegepersonen, um die derzeitige Vorgehensweise zu reflektieren und neue Erkenntnisse für ein effektives Schmerzmanagement zu erhalten.
- Die Pflegeentwicklung, um aus den Ergebnissen eine Anpassung des Schmerzstandards bzw. Handlungsleitlinien vornehmen zu können.
- Pflegende, mit der Möglichkeit die Pflegequalität zu verbessern.
- Pflegeentwicklung, um aus den Ergebnissen Schulungen ableiten zu können bzw. für die Erstellung von Schulungskonzepten.
Datenset & Spezifikation
Nach Abschluss und Evaluierung von Phase 1 konnte mit Phase 2 „Datenset & Spezifikation“ gestartet werden.
Zentrales Interesse in Phase 2 ist zu bestimmen, welche Datenelemente relevant sein könnten. Wir sind daher folgender Frage nachgegangen:
„Welche Datenelemente lassen sich aus der Literatur ableiten, die das Phänomen Schmerz ganzheitlich erfassen könnten“?
In einer umfassenden Literaturrecherche und im Gespräch mit FachexpertInnen konnten 85 Datenelemente extrahiert werden. Diese wurden anschließend in 16 Konzepten geclustert und wie in Abbildung 2 zu sehen, in einem Mindmap visualisiert.
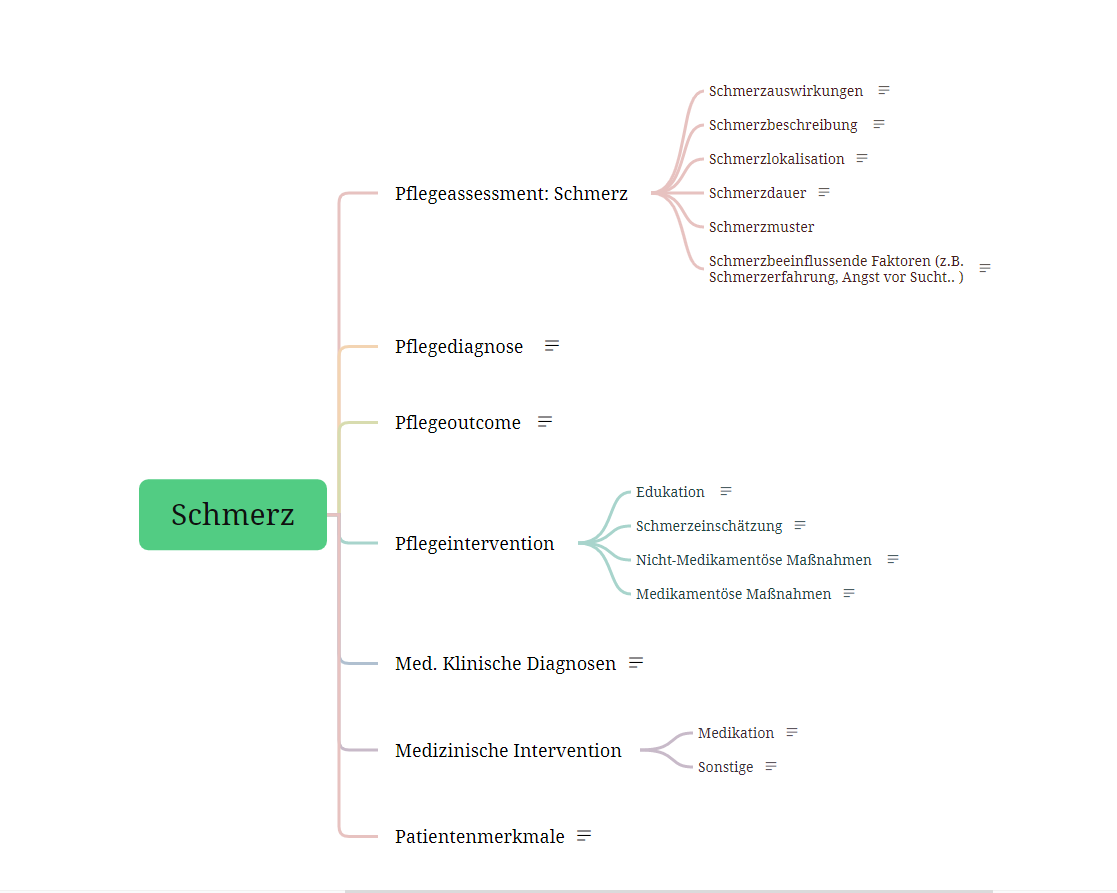
Darstellung der Clusterung von Datenelemente in 16 Konzepten aus dem Themenbereich „Schmerz“
Aber werden diese aus der Literatur extrahierten Datenelemente auch wirklich irgendwo dokumentiert?
Um das zu beantworten brauchte es wieder die ExpertInnen in der Praxis. In einer Ist-Analyse wurde die gesamte Routinedokumentation auf der Suche nach möglichen Datenelementen durchforstet. Hilfreich war dazu den gesamten Dokumentationsprozess anhand eines Szenarios mit der BPMN- Methode zu modellieren. Die folgende Abbildung zeigt einen kleinen Ausschnitt der Modellierung des präparativen Dokumentationsprozesses im Schmerzmanagement.
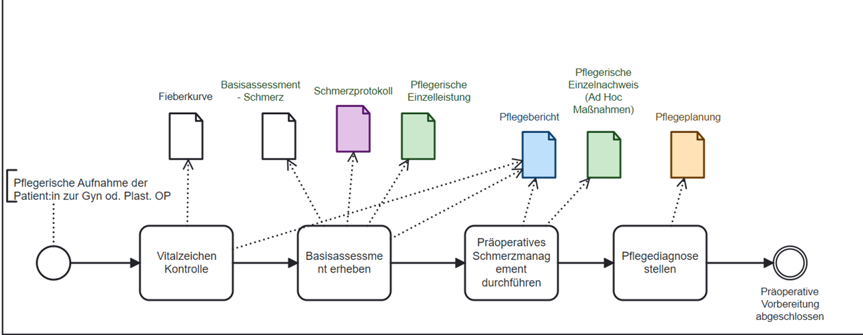
Präoperativer Dokumentationsprozess
Weitere Schritte
In Phase 3 ist nun weiters vorgesehen, im bestehenden Dokumentationsprozess einzelne Adaptierungen vorzunehmen, um wesentliche Datenelemente aus dem theoretischen Datenset standardisiert zu erfassen. Was hier genau adaptiert und wie das in den Routinebetrieb integriert wurde, folgt in einem weiteren Blogbeitrag.